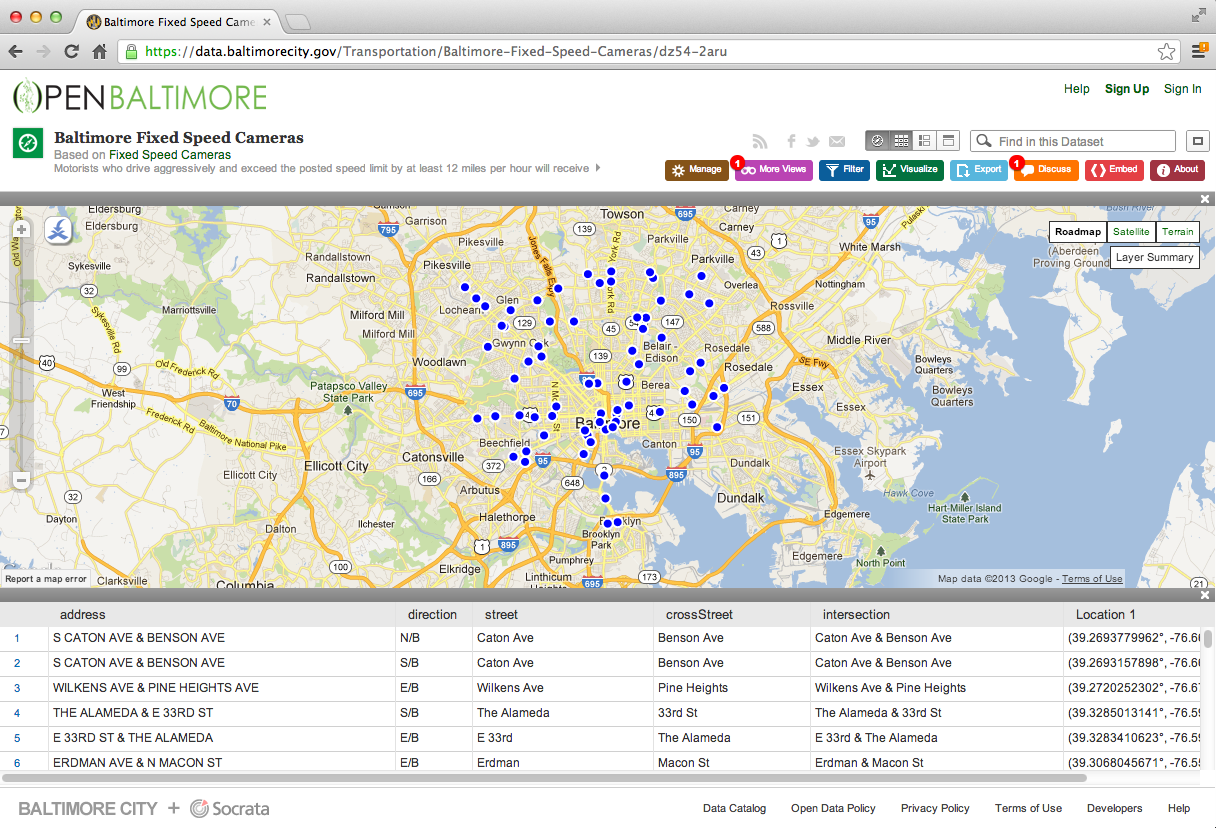
https://data.baltimorecity.gov/Transportation/Baltimore-Fixed-Speed-Cameras/dz54-2aru
Jeffrey Leek
Johns Hopkins Bloomberg School of Public Health
https://data.baltimorecity.gov/Transportation/Baltimore-Fixed-Speed-Cameras/dz54-2aru
if(!file.exists("./data")){dir.create("./data")}
fileUrl <- "https://data.baltimorecity.gov/api/views/dz54-2aru/rows.csv?accessType=DOWNLOAD"
download.file(fileUrl,destfile="./data/cameras.csv",method="curl")
cameraData <- read.csv("./data/cameras.csv")
names(cameraData)
[1] "address" "direction" "street" "crossStreet" "intersection" "Location.1"
tolower(names(cameraData))
[1] "address" "direction" "street" "crossstreet" "intersection" "location.1"
splitNames = strsplit(names(cameraData),"\\.")
splitNames[[5]]
[1] "intersection"
splitNames[[6]]
[1] "Location" "1"
mylist <- list(letters = c("A", "b", "c"), numbers = 1:3, matrix(1:25, ncol = 5))
head(mylist)
$letters
[1] "A" "b" "c"
$numbers
[1] 1 2 3
[[3]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 6 11 16 21
[2,] 2 7 12 17 22
[3,] 3 8 13 18 23
[4,] 4 9 14 19 24
[5,] 5 10 15 20 25
http://www.biostat.jhsph.edu/~ajaffe/lec_winterR/Lecture%203.pdf
mylist[1]
$letters
[1] "A" "b" "c"
mylist$letters
[1] "A" "b" "c"
mylist[[1]]
[1] "A" "b" "c"
http://www.biostat.jhsph.edu/~ajaffe/lec_winterR/Lecture%203.pdf
splitNames[[6]][1]
[1] "Location"
firstElement <- function(x){x[1]}
sapply(splitNames,firstElement)
[1] "address" "direction" "street" "crossStreet" "intersection" "Location"
http://www.plosone.org/article/info:doi/10.1371/journal.pone.0026895
fileUrl1 <- "https://dl.dropboxusercontent.com/u/7710864/data/reviews-apr29.csv"
fileUrl2 <- "https://dl.dropboxusercontent.com/u/7710864/data/solutions-apr29.csv"
download.file(fileUrl1,destfile="./data/reviews.csv",method="curl")
download.file(fileUrl2,destfile="./data/solutions.csv",method="curl")
reviews <- read.csv("./data/reviews.csv"); solutions <- read.csv("./data/solutions.csv")
head(reviews,2)
id solution_id reviewer_id start stop time_left accept
1 1 3 27 1304095698 1304095758 1754 1
2 2 4 22 1304095188 1304095206 2306 1
head(solutions,2)
id problem_id subject_id start stop time_left answer
1 1 156 29 1304095119 1304095169 2343 B
2 2 269 25 1304095119 1304095183 2329 C
names(reviews)
[1] "id" "solution_id" "reviewer_id" "start" "stop" "time_left"
[7] "accept"
sub("_","",names(reviews),)
[1] "id" "solutionid" "reviewerid" "start" "stop" "timeleft" "accept"
testName <- "this_is_a_test"
sub("_","",testName)
[1] "thisis_a_test"
gsub("_","",testName)
[1] "thisisatest"
grep("Alameda",cameraData$intersection)
[1] 4 5 36
table(grepl("Alameda",cameraData$intersection))
FALSE TRUE
77 3
cameraData2 <- cameraData[!grepl("Alameda",cameraData$intersection),]
grep("Alameda",cameraData$intersection,value=TRUE)
[1] "The Alameda & 33rd St" "E 33rd & The Alameda" "Harford \n & The Alameda"
grep("JeffStreet",cameraData$intersection)
integer(0)
length(grep("JeffStreet",cameraData$intersection))
[1] 0
http://www.biostat.jhsph.edu/~ajaffe/lec_winterR/Lecture%203.pdf
library(stringr)
nchar("Jeffrey Leek")
[1] 12
substr("Jeffrey Leek",1,7)
[1] "Jeffrey"
paste("Jeffrey","Leek")
[1] "Jeffrey Leek"
paste0("Jeffrey","Leek")
[1] "JeffreyLeek"
str_trim("Jeff ")
[1] "Jeff"